The XPath package comes with a custom GTInspector. Pressing Cmd+I on an XPath object (which can be created by sending a string #asXPath) will bring it up.
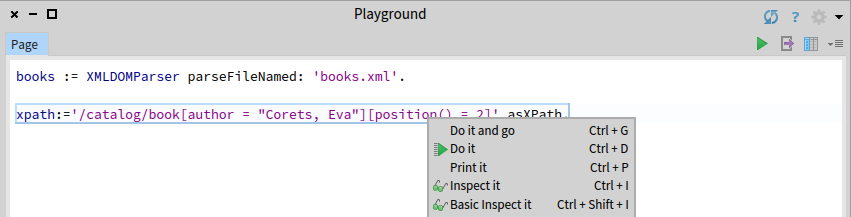
Source tab
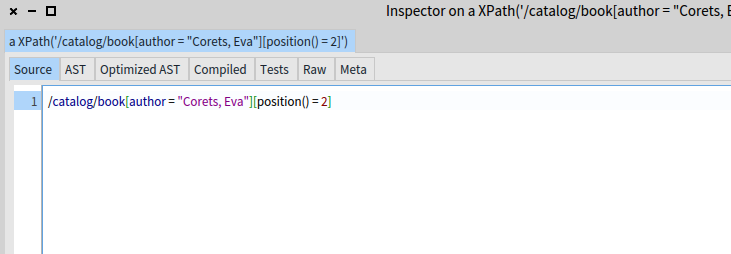
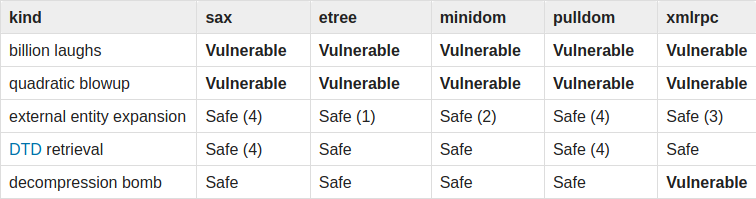
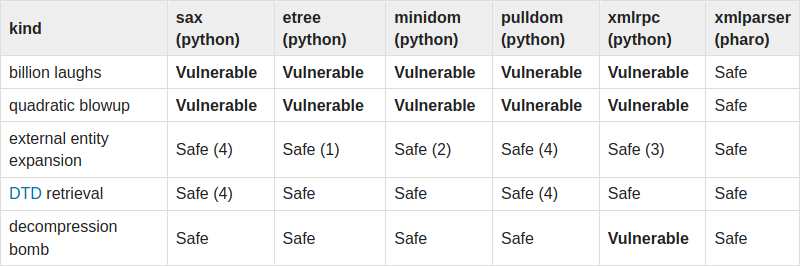
The Source tab displays the XPath source code with syntax highlighting. The highlighting was implemented with a new expression parser handler class that just tracks the start and end positions of syntax constructs instead of building an AST, and with the XMLParser GT highlighting classes to highlight those constructs. We need this position-tracking parser handler even if our AST already supports printing with syntax highlighting, because the transformation from source to AST (even before optimization) discards things like non-significant whitespace, making it impossible to reproduce the original source. It’s also inefficient to generate a full AST when we only need token positions.
The default colors chosen to highlight XPath are based on the colors used to highlight Smalltalk, so similar constructs are highlighted the same way (strings, numbers, and blocks in the example).

The Source tab is also editable. Pressing Cmd+s (or clicking the green checkmark) accepts the edits and updates the XPath object. Cmd+z (or the purple arrow) reverts the edits.
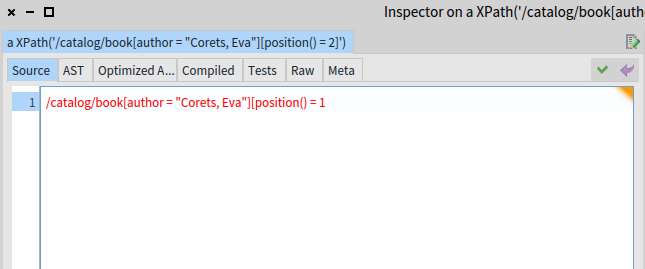
Invalid syntax edits (like the missing “]” above) are highlighted using red.
AST tab

The AST tab displays a navigable tree of AST node objects. Clicking on an arrow expands a node, and clicking on a node brings up a right pane with AST node subtree and source tabs for the node you clicked on.
Optimized AST tab

The Optimized AST tab shows the resulting AST after it has been optimized. Notice that the [position() = 2] predicate was simplified to [2]. Like the AST tab, the subtree and source tabs in the right pane are generated from the AST node you click on in the left pane.
Compiled tab
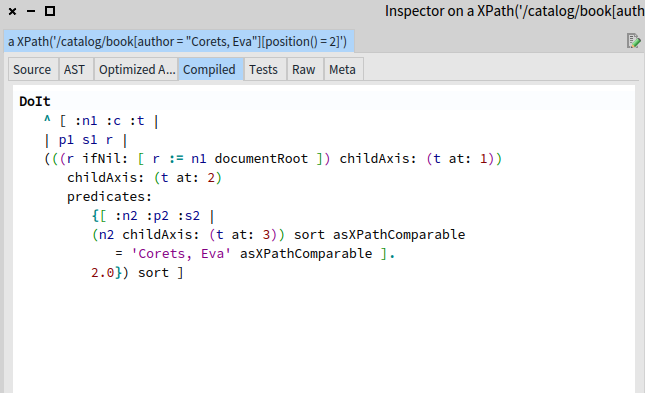
The Compiled tab shows the Smalltalk code that the optimized XPath AST is translated into, which is compiled using the system compiler before evaluation.
Conclusion
The XPath GTInspector is useful for both users and maintainers. User get an XPath editor with syntax highlighting and syntax checking, while maintainers can quickly compare XPath source with its AST, optimized AST, and generated Smalltalk code.